

引き続き「データ分析の教科書」について
以前の記事で日立製作所のLumada Data Science Lab が監修したデータ分析の教科書 (リックテレコム社)の4.5節の画像処理の例でつまづいたところを解説しました。久しぶりの続編となった今回はその次の「4.6節テキスト解析(文章分類)」について書きます。というのも、自分で試してみるとかなりハマりましたので備忘録代わりに書いておきます。
その前に、自然言語処理について
テキスト解析、自然言語処理 (NLP)といえばかなり幅広く、最近はディープラーニングを使うBERT (Bidirectional Encoder Representations from Transformers)がホットに。さらに2022年11月のOpenAI 社によるChatGPT の登場で、自然言語処理を知らない一般の方でも「チャットGPTは知っている」となるほどになりました。今やNLP の空前のブームと言って良いでしょう。
一方でこのデータ分析の教科書でのテキスト解析はかなりあっさりしていて、BERT を使った文章分類の例がある程度。NLP 特有のトークン化やワードクラウドとかの話はありません。ビジネスで使えるデータサイエンスについて的を絞った書籍なので、これだけでも味見は十分なのですが、NLP は本当に幅広いです。
この分野を極めたい場合は、オライリー社が2022年2月に出版した「実践 自然言語処理」を読んでサンプルを試すとかなり力が付きます。512ページもある本の分厚さとNLP にこんなに分野があることに驚かされました。ただ、元言語が英語の書籍なので、日本語特有のコツは本編にはありません。例えば、サンプルのスクリプトで、テキストファイルを英語のものから日本語のものに変えただけで、単語の分割がうまくできなかったり、ワードクラウドを描画するにも日本語のフォントが対応していなくて「□」と表示されてしまったり。付録に日本語向けの内容もあるのですが、もうちょっと色々知りたいな、と思いました。
またBERT についてもオーム社の「BERTによる自然言語処理入門」という書籍があります。データ分析の教科書ではBERT による文章分類の例だけでしたが、オーム社の本ではBERT でかなり色々できることが分かります。
他にもNLP の書籍はありますが、最初はオライリーとオームの本を読めば良いかなと思います。そしてサンプルを実践するためだけにデータ分析の教科書に戻ってくる、という流れのほうが理解が深まってから実際に動かせるので良いでしょう。
そもそもデータが足りなかった
リックテレコムのHP にデータ分析の教科書のソースコードのダウンロードページがあります。
https://www.ric.co.jp/book/data-sience/detail/1875
ダウンロードに必要なユーザー名とパスワードは書籍に書かれています。
2021年8月に出版された初版すぐに購入して翌9月にこのサンプルをダウンロードしたとき、4.6 のサンプルの中に尼崎市のデータのCSV が含まれていませんでした。書籍には手動でラベル付けしたもの、との説明があったので「これはユーザー側でCSV を用意させるってこと?」と捉え、「どんな教師データか分からないから無理だよね」と思い、サンプルは試せずにいました。
すると、2023年5月になって再度ダウンロードしてみると、4.6 フォルダーにCSV ファイルが含まれています。タイムスタンプを見ると2022年1月の日付になっているので、後から追加されたことが分かります。知らなかった…
import Adam でエラー
早速Python 3.9 の環境で「BERTサンプル_質問文のみ.ipynb」を試してみると、いきなりエラー。
ImportError Traceback (most recent call last)
c:\Book3001\4.6_Text\BERTサンプル_質問文のみ.ipynb セル 2 in ()
20 from keras.models import Model, Input, load_model
21 from keras.layers import Dense, GlobalAveragePooling1D, Dropout
---> 22 from keras.optimizers import Adam
23 from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
25 pd.set_option("display.max_columns", 30)
ImportError: cannot import name 'Adam' from 'keras.optimizers' (c:\Python39\lib\site-packages\keras\optimizers.py)Code language: JavaScript (javascript)どうやらstack overflow の情報によると、Keras のバージョンが上がった際にAdam がKeras ではなくkeras.optimizers ではなくkeras.optimizers_v1 に移行したとか、tensorflow.keras.optimizers に入ったとかの情報が。
とりあえずimport の部分を以下のように変更して動くようになりました。
#from keras.optimizers import Adam
from tensorflow.keras.optimizers import AdamCode language: CSS (css)FileNotFoundError が発生
続いてはFileNotFoundError が出ました。
FileNotFoundError Traceback (most recent call last)
c:\Book3001\4.6_Text\BERTサンプル_質問文のみ.ipynb セル 6 in ()
1 #尼崎市のオープンデータに手動でラベル付け
2 fname = "sample_input_amagasaki_label.csv"
----> 4 df_label = pd.read_csv("./input/" + fname)
5 df_label = df_label.fillna(0)
6 print(df_label.shape)
File c:\Python39\lib\site-packages\pandas\util\_decorators.py:311, in deprecate_nonkeyword_arguments..decorate..wrapper(*args, **kwargs)
305 if len(args) > num_allow_args:
306 warnings.warn(
307 msg.format(arguments=arguments),
308 FutureWarning,
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
File c:\Python39\lib\site-packages\pandas\io\parsers\readers.py:680, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
665 kwds_defaults = _refine_defaults_read(
666 dialect,
667 delimiter,
(...)
676 defaults={"delimiter": ","},
677 )
...
796 else:
797 # Binary mode
798 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: './input/sample_input_amagasaki_label.csv'
Code language: PHP (php)すごい長いエラーですが最後の行にある、「sample_input_amagasaki_label.csv」が無いというのが原因です。
data フォルダーに置いていたのですが、これではダメで、input フォルダーを作ってその下にCSV ファイルを置く必要がありました。
findfont のエラー
さらにエラーは続きます。
findfont: Font family ['IPAexGothic'] not found. Falling back to DejaVu Sans.Code language: CSS (css)今度は、指定しているIPAexGothic フォントが無いというエラーで、出力される棒グラフも横軸の日本語ラベルが「□」で表示されてしまっています。
追加でIPAexGothic フォントをダウンロードしても良いのですが、とりあえず今Windows に入っているフォントで表示されれば良いので、MS ゴシックのフォントに変更しました。
#plt.rcParams['font.family'] = 'IPAexGothic'
plt.rcParams['font.family'] = 'MS Gothic'Code language: Python (python)すると棒グラフの出力がうまくいきました。
HTTPError: 401 Client Error のエラー
続くエラーは東北大学の日本語BERT を使ってトークン化するところ。
HTTPError Traceback (most recent call last)
c:\Book3001\4.6_Text\BERTサンプル_質問文のみ.ipynb セル 14 in ()
1 ##### BERT
2 # トークナイザー
3 # 事前にダウンロード。https://github.com/cl-tohoku/bert-japanese
4 # BERT-base_mecab-ipadic-bpe-32k_whole-word-mask.tar.xz
----> 5 tokenizer_bert = BertJapaneseTokenizer.from_pretrained("./pre_trained/BERT-base_mecab-ipadic-bpe-32k_whole-word-mask")
6 # 学習済モデルの読み込み
7 model_bert = BertModel.from_pretrained("./pre_trained/BERT-base_mecab-ipadic-bpe-32k_whole-word-mask")
File c:\Python39\lib\site-packages\transformers\tokenization_utils_base.py:1763, in PreTrainedTokenizerBase.from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1761 resolved_vocab_files[file_id] = None
1762 else:
-> 1763 raise err
1765 if len(unresolved_files) > 0:
1766 logger.info(
1767 f"Can't load following files from cache: {unresolved_files} and cannot check if these "
1768 "files are necessary for the tokenizer to operate."
1769 )
File c:\Python39\lib\site-packages\transformers\tokenization_utils_base.py:1724, in PreTrainedTokenizerBase.from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1722 else:
1723 try:
-> 1724 resolved_vocab_files[file_id] = cached_path(
...
1018 )
1020 if http_error_msg:
-> 1021 raise HTTPError(http_error_msg, response=self)
HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/pre_trained/BERT-base_mecab-ipadic-bpe-32k_whole-word-mask/resolve/main/vocab.txt
Code language: PHP (php)こちらは最後の行にある、HTTPError: 401 Client Error が原因です。
事前に「BERT-base_mecab-ipadic-bpe-32k_whole-word-mask.tar.xz」をダウンロードして解凍しておけば良いのですが、コメント文にある「https://github.com/cl-tohoku/bert-japanese」のGit でブランチやタグを切り替えても「BERT-base_mecab-ipadic-bpe-32k_whole-word-mask.tar.xz」が見つかりません。
仕方ないのでググって東北大学のHP (https://www.nlp.ecei.tohoku.ac.jp/~m-suzuki/bert-japanese/) から該当のファイルをダウンロードしました。ファイルサイズが2GB もあるのでダウンロードに時間が掛かりました。
tar.xz を解凍してpre_trained フォルダーに置いておけば完璧です。これでJupyter Notebook で最後まで実行できるようになりました。
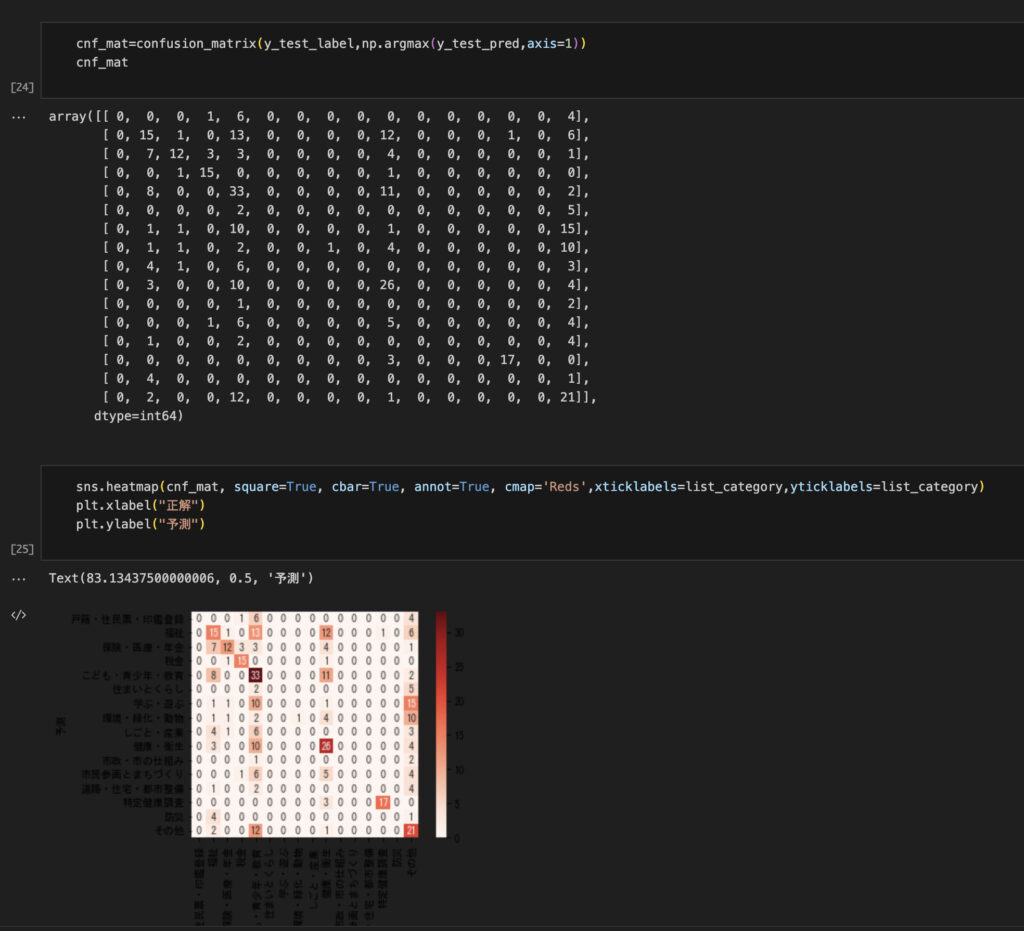
上記はWindows で実行した結果付きのipynb ファイルをMacOS で開いたスクリーンショットです。
いやぁ、今回もハマりながらの実践でした。





No responses yet