国や自治体の公開データで多いPDF
国や自治体の公開データを活用することが増えてきました。
私はよくシチズン・データサイエンスの端くれみたいな活動をして、人口データで年齢別や地域別の遷移を見たります。
自治体のホームページでは、PDF ファイルで公開されていることが多いです。
たとえば、こんなデータ。これはある市がホームページで公開している年齢別の人口データ。元データはExcel の表だったと思われますが、公開しているデータはPDF ファイルになっています。
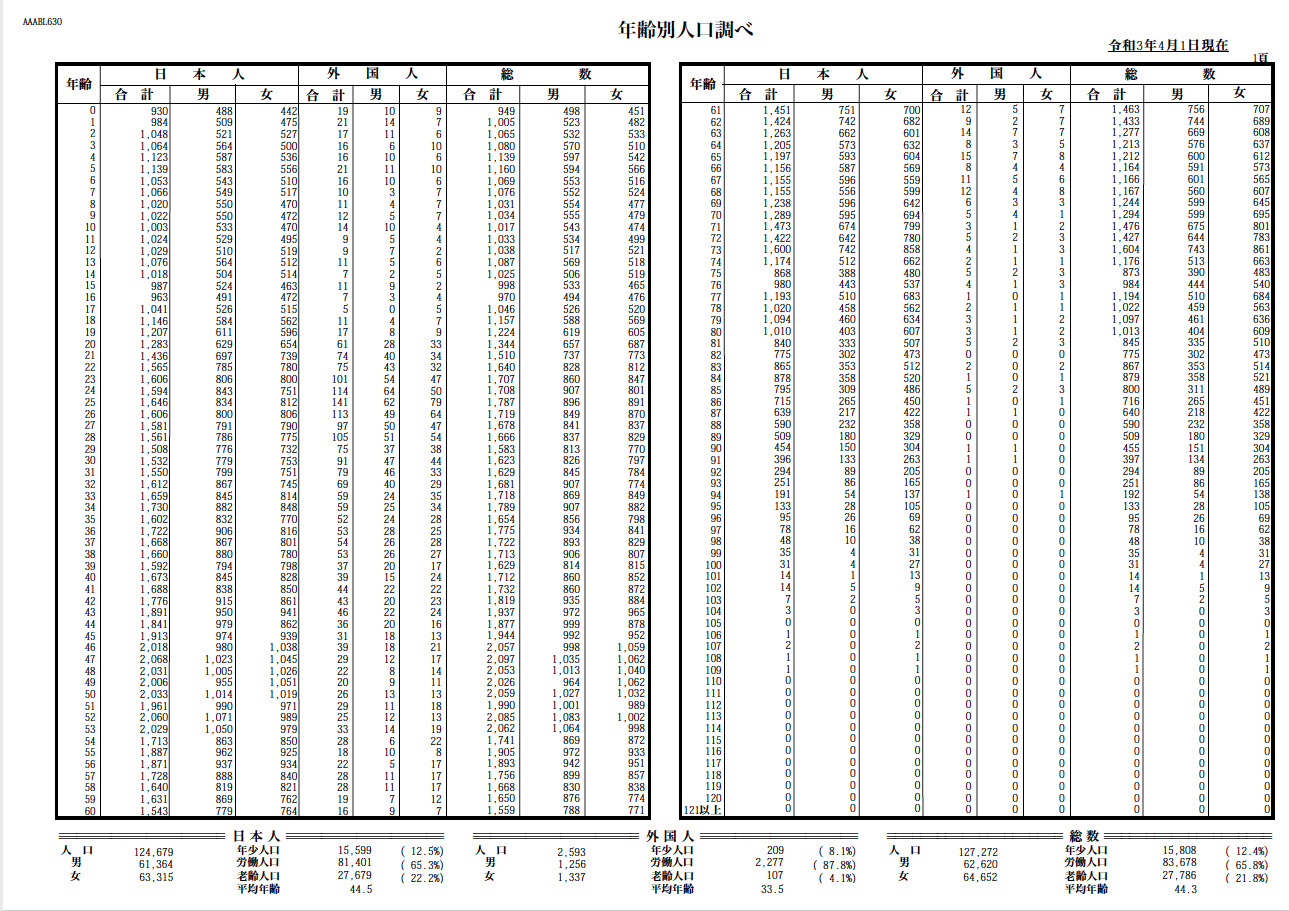
以前はこうしたPDF ファイルを手動でコピペしてExcel ファイルにしていましたが、どうしても時間が掛かりますし、ヒューマンエラーが発生しがちです。
PDF をCSV に変換するツールがあればもっと楽になるのに、と思いました。
世の中、オンラインでPDF ファイルをアップロードすればCSV にしてくれる変換ツールがありますが、アップロードするとサーバー側にデータが残ってしまいますし、ファイルを1個1個変換していくのは手間ですよね。
そこでプログラミングで変換できるツールを探しました。
Python のtabula-py でPDF をCSV に変換
ググると最初にPython のtablura-py というパッケージの情報が多かったのでそれを使ってみることに。実行環境ではPython (2021年10月時点では3.6 以上)だけでなくJava (同8以上)が必要になります。Python からJava のライブラリを呼んでいるようです。
まずはtabula-py をインストールします。
pip install tabula-pyCode language: DOS .bat (dos)そしてPython スクリプトから使ってみました。
tabula.convert_into コマンドでPDF からCSV に変換できます。
import tabula
df = ("xxx.pdf")
output = "converted_xxx.csv"
tabula.convert_into(df, output, output_format="csv", pages='1', java_options="-Dfile.encoding=SHIFT_JIS")
Code language: Python (python)このPDF ファイルでは2ページ目以降は違う表形式になっていたので、pages=’1′ で1ページ目だけを変換対象としています。また、tabula のデフォルトのエンコードはUTF-8 ですが、このPDF では日本語ドキュメントに多いSHIFT_JIS でエンコードされていたので、オプションで指定しています。
日本語のPDF ファイルは結構変換に失敗するので、あれこれオプションを指定しないとうまくいかないケースが多かったです。
Python スクリプト実質3行でできるのは魅力的なのですが、エンコードなどの基本的なオプションも含めてJava オプションで指定しないといけないのは結構不便でした。
結局Java のラッパーを叩いているだけなら、Java の本家を使った方が良さそうと思い、この度はtabula-java を使ってみました。
Java のtabula-java でPDF をCSV に変換
Java にはtabula-java というパッケージがGitで公開されています。ソースコードもダウンロードできますが、リリースリンクからjar ファイルのダウンロードも可能です。2021年10月時点の最新版は1.0.5 (ファイル名:tabula-1.0.5-jar-with-dependencies.jar)でした。
jar ファイルをコマンドプロンプトからjava コマンドで実行します。
java -jar tabula-1.0.5-jar-with-dependencies.jar -p 1 -o converted_xxx.csv xxx.pdf -g -tCode language: DOS .bat (dos)オプションの意味はGit のUsage Examples にありますが、-p で変換元PDF ファイルの対象ページ、-g でページの変換対象エリアを自動推測させる、-t でストリーム形式で読み込ませるなどのオプションを使いました。
この辺りのオプションは対象PDF ファイルによって使ったほうが良い場合もあれば無いほうが良い場合もありますので、試行錯誤は必要かなと思います。
CSV 変換後の作業
ただ、CSV ファイルに変換できたからと言って、それで終わりではありません。やはり変換しきれない場合もあれば、セル値が欠損してしまうということもあります。データが欠けてしまった場合は、変換時のオプションを変えて欠損しないことを優先してCSV に変換したほうが良いです。
また、セル値に複数のカラム(列)データが入ってしまうことがあります。
例えば3列のカラムがあった場合に、
| col1 | col2 | col3 |
|---|---|---|
| 1 | 2 | 3 |
変換後のCSV ファイルでは
| col |
|---|
| 1 2 3 |
のように1 つのカラムに3 カラムのデータが入ってしまうことはよくあります。
変換ツールではそこまで完璧にCSV に変換できないので、そこはプログラミング言語側でCSV ファイルを読み取った後の前処理で直していくやり方が良いように思えます。





No responses yet